背景
QAエンジニアの代慶です!
Rubyのマルチスレッドプログラミングで思いもよらぬ挙動が起こることを知ったので、 それを記事としてまとめてみます。
結論
以下のサンプルコードで自分が期待していない挙動が起こりました。
class A def initialize end def method(param) @result = params # 処理①:インスタンス変数の更新 sleep 0.0001 # 処理②:長く時間のかかる処理 @result # 処理③:インスタンス変数の参照 end end a_instance = A.new [1, 2].map do |i| Thread.new do puts a_instance.method(i) end end.map(&:join)
出力結果 2 2
え。なんで、 A.new.method(1) の結果が 1 ではなくて、 2 になるのという疑問を思ったので、そこをいくつかの前提知識も含めて勝手に解説していきます。
前提の理解
- Rubyのマルチスレッドプログラミング
- GVLで制御されているスレッドの切り替えタイミング
Rubyのマルチスレッドプログラミングとは?
マルチスレッドプログラミングを話す前に、その前提となるCPUとプロセスとスレッドについてです。
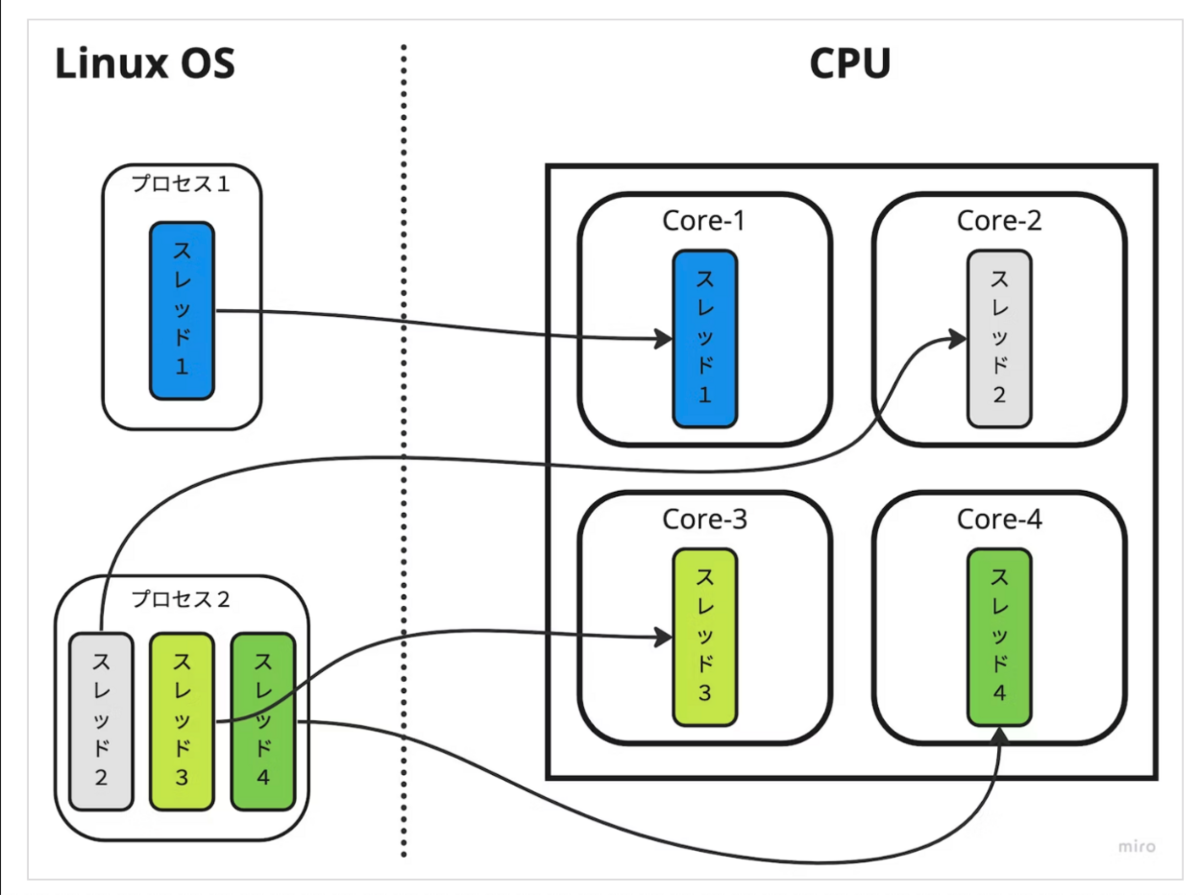
プロセスとCPUの物理コア( =スレッド)について
Linux OS 上で実行中のプログラムはプロセスと呼ばれます。 プロセスは最低1つのスレッドを持ち、このスレッドが CPU の1物理コア上で実行される単位になります。
また、プロセスとスレッドの大きな違いとしては、複数のプロセス間ではメモリ領域を共有しないのに対して、複数のスレッド間ではメモリ領域を共有することです。
インスタンス変数である @result は、スレッド間で共有されていたデータでした。
シングルスレッドとマルチスレッドについて
シングルスレッドとマルチスレッドは文字通り、スレッドを一つしか使わないのが、シングルスレッド。スレッドを複数使うのが、マルチスレッドになります。
マルチスレッドを利用する理由としては、性能効率を上げるためです。 単一のスレッドしか用いないシングルスレッドでは、CPUを効率よく使い切ることができません。 CPUの1物理コアが1スレッドに対応しているため、1スレッドを使うだけでは複数あるコアのうち利用されていないコアが出てきてしまいます。

RubyとJavaのマルチスレッドプログラミング
Rubyは、マルチスレッドプログラミングですが、Javaとは少し違います。 Javaはプロセス中で同時に実行できるスレッド数は複数あるのに対して、Rubyは1つしかありません。 つまり、Javaは並列処理、Rubyは並行処理になっています。

何が違うかというと、RubyにはGVL 機構(Global VM Lock)というのがあり、排他制御を開発者が意識しなくて良いようにしてくれており、その結果並行処理になっています。
良いように書いたのですが、並列処理の方が並行処理よりパフォーマンス面で良さそうに感じます。それなのに、どうしてGVL機構のようなものがあるのでしょうか。 ここの前提には、排他制御を行うことの難しさがあるようです。
並列処理を行ったJavaのプログラミングでは、以下のような問題がよく起こるようです。
- デッドロック
- レースコンディション
デッドロックのサンプルコード
Object resource1 = new Object(); Object resource2 = new Object(); Thread thread1 = new Thread(() -> { synchronized (resource1) { // resource1のロックを取得 sleep(100); synchronized (resource2) { // resource2のロックを取得 // Access to resources } // resource2のロックを解除 } // resource1のロックを解除 }); Thread thread2 = new Thread(() -> { synchronized (resource2) { // resource2のロックを取得 sleep(100); synchronized (resource1) { // resource1のロックを取得 // Access to resources } // resource1のロックを解除 } // resource2のロックを解除 }); thread1.start(); thread2.start();

そのため、開発者が排他制御を意識せずに、よしなにやってくれるGVL機構がRubyにはあります。
GVL機構によって、スレッドの制御は行われるのですが、なぜサンプルコードで見たような事象が起こったのでしょうか。
それは、GVL機構におけるスレッド処理の切り替えタイミングの影響があります。
GVLで制御されているスレッドの切り替えタイミング
GVLで制御されているスレッドの切り替えタイミングについてみていきます。 gvl-tracingというgemがあるので、このgemを使ってスレッドの可視化を行い、検証をしていきます。
(gvl-tracingはRuby 3.2 から使えます。)
RubyKaigi 2023 - Understanding the Ruby Global VM Lock by Observing it - Google スライド
ソースコードによると、処理するスレッドの切り替えが発生する要因としては以下がありそうでした。
- 時間による切り替え
- I/O待ちやsleep処理後の切り替え
- 例外処理による切り替え(今回扱わない)
まずは、時間による切り替えについてみていきます。
時間による切り替え
ソースコードによると、100 msごとに処理が切り替わるようになっていることがわかりました。
実際に可視化したスレッドの情報を見てみます。
以下の処理はメインスレッドとは別にスレッドを2つ作成し、その中でそれぞれ1s経過するまでひたすら 1 + 1 の処理を実行させるものです。
CPUが処理を待つことはないので、どの時間間隔で処理が切り替わるかが見えます。
require "gvl-tracing" def main GC.disable # GCが実行された場合も結果のグラフに現れていました。今回はノイズになるのでオフにしました。 end_time = Time.now + 1 while Time.now < end_time do # 1s間ひたすら 1 + 1 を実行させる 1 + 1 end GC.enable end GvlTracing.start("example1.json") do 2.times.map do |i| Thread.new do # メインスレッドとは別に2つのスレッドで、1 + 1の処理を実行 main end end.map(&:join) end
gvl-tracingの可視化の結果です。

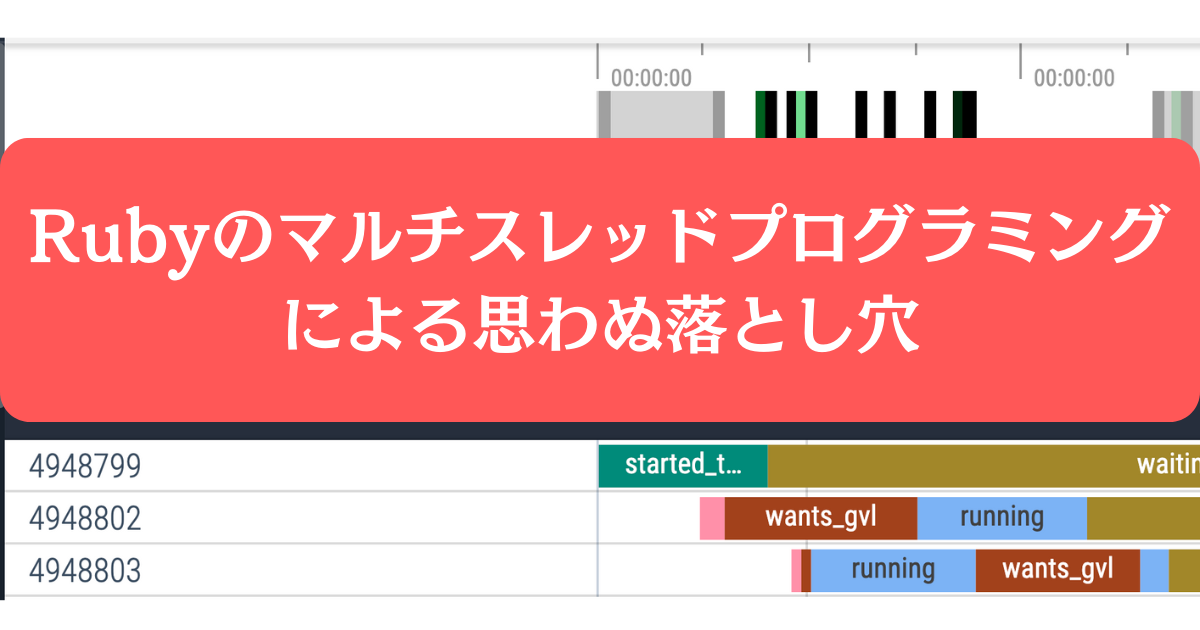
メインスレッドは処理がされていませんが、thread_id:3302228と3302229のスレッドが100 msごとに実行と待ち状態を切り替えているのがわかります。
各ステータスの意味
waiting:network / IO / sleep などによる処理待ち
runnning:処理中
wants_gvl:処理実行可能、GVLの取得待ち
スレッドの数を5にしたときには、以下のようになります。

実際に、100 msごとに処理が切り替わるようになっていることがわかりました。
I/O待ちやsleep処理後の切り替え
次に、I/O待ちやsleep処理後の切り替えがどのようになっているかをみていきます。 メインスレッドとは別に、2つのスレッドで計算処理をした状態で、もう1つのスレッドでsleepを用いて処理待ちを再現します。
※ 時間による切り替えに影響を受けないように演算処理の時間を0.01s、sleepを0.001sにした。
require "gvl-tracing" def main GC.disable end_time = Time.now + 0.01 while Time.now < end_time do 1 + 1 end puts "0.01秒間で1 + 1の計算が完了しました。" GC.enable end GvlTracing.start("example1.json") do GC.disable thread = Thread.new do sleep 0.001 end two_threads = 2.times.map do |i| Thread.new do main end end thread.join two_threads.map(&:join) GC.enable end
可視化の結果です。

sleep処理を実行しているスレッドID 375563 のスレッドはsleep処理後に waiting となり、その間他のスレッドに処理が渡っていることがわかります。
一点、気になったのはsleepの waiting 後にすぐに処理が実行されるわけではなく、タスク待ち wants_gvl の状態になってから、処理が実行されています。
先にタスク待ちの状態になっているスレッドが優先的に処理されるのでしょうか。
スレッドの数を5にして確認してみます。

先にタスク待ち wants_gvl の状態になっているスレッドが優先的に処理されるのでしょうか。
この仮説が正しければ、スレッドの数が増えればタスク待ち wants_gvl の状態は長くなるはずです。
スレッドが2つの場合は、処理が実行できるようになってから、約20 msの待ち時間が発生していましたが、スレッドが5つの場合は、約50 msの待ち時間が発生しています。
このようになっている理由はsleep処理を実行完了した後に、既に自分以外のスレッドの多くがタスク待ちの状態になっているため、最初にタスク待ちとなったスレッドが優先的に処理されるためだと考えられます。
ここまでの前提の理解の部分をまとめると以下のことがわかりました。
- Rubyはマルチスレッドの並行処理がされており、同一タイミングでは一つのスレッドしか動かない
- スレッド間の制御はGVLによって行われ、スレッドの処理が切り替わるタイミングは以下になる
- 時間による切り替え:100 msごと
- I/O待ちによる切り替え:即時
事象が発生した理由
改めて、最初のサンプルコードを見てみましょう。
class A def initialize end def method(params) @result = params # 処理①:インスタンス変数の更新 sleep 0.0001 # 処理②:長く時間のかかる処理 @result # 処理③:インスタンス変数の参照 end end a_instance = A.new [1, 2].map do |i| Thread.new do puts a_instance.method(i) end end.map(&:join)
こちらの中の動きをgvl-tracingで可視化すると以下のようになっています。

ここでわかることは、処理が先に行われているスレッドID 4472754 が waiting に入っている間に処理がスレッドID 4472755 に切り替わっているということです。
裏側で起こっていることは以下の図のようになっていると考えられます。

- GVL機構により、スレッド1がsleep処理に入ったタイミングで、スレッド2に切り替わる。
- スレッド間で共有されるインスタンス変数である
@resultは元々1が入っていたにも関わらず、2に書き変わる。 - 再びスレッド1に処理が切り替わる。
- 値が
2に変わった@resultを参照して、 スレッド1においても2が出力される。
※処理② には、sleepであれ、DBへのアクセスをするようにI/O待ちが発生する処理出会っても、同様の事象が起こります。
感想
今回のサンプルコードは実際のプロダクト開発において、あまり見ないかもと思ったかもしれませんが、 Rails のアプリケーションでもサンプルコードのようなロジックを含むAPIに対して、複数ユーザーから同時アクセスされると同様の事象は起きてしまいます。
その時には、情報漏洩なんて事態にもなるかもしれません。
私はQAエンジニアとして活動していますが、品質保証をするとなった時よく想起されるのはテストフェーズですよね。 ただ、今回の事象などを見て、そもそもマルチスレッドの気をつけるべき点などを理解していないと、テスト観点としても出てこないし、 テストすべきかの判断もつかないと思いました。
なので、要件・設計・実装・テストのフェーズがあった時に、できるだけ左側のフェーズで気をつけるべき点を防いで 少しずつ品質保証をしていくことが大事だなと思いました。また、その大前提として、目に見える挙動の裏で起こっていることを深く理解する必要があると感じました。
安心した状態で高速にリリースができるように、テストフェーズ以外の部分にもガンガン足を突っ込んで 良い開発者体験を提供したいと思います。
備考
Ruby 3.0以降ではRactorと呼ばれるものが導入されています。
Ractorは、これまで並行処理しかできなかったRubyのマルチスレッドプログラミングで並列処理を可能にします。
今回の話で、ただ並列処理を可能にするのは危険だと思うのですが、並列処理のマルチスレッドプログラミングをデメリットを抑えるために、Ractor(Ractorは1つ、または複数のスレッドを有します。)間での共有できるデータが限定されているようです。
Ractorを利用することで、演算処理で実行時間がかかっていた箇所の性能改善ができることが期待されます。 もちろん、DBアクセスのI/O待ちが多い処理においては既に既存の処理で賄えているため、効果は高くありません。
※ 最近のRuby会議で話されており、まだまだ課題は山積みで、利用実績も少ないようですが、 試したらまた共有できたらと思います。